From Screenplay to Storyboard with DSPy
How I used DSPy, GEPA optimization, and GPT-5 to turn a raw screenplay into a fully structured visual storyboard with reusable, linked assets.
A friend sent me the screenplay of a short film he was developing and asked if I could help. Not with the script, with the storyboard. He wanted every scene broken into shots, every character described with enough detail for an illustrator, every prop catalogued, and all of it merged together into a complete visual storyboard, scene by scene.
I thought that sounded like something AI should be able to do. So I built it.
Why storyboards are hard to automate
A storyboard artist works through a screenplay methodically. They read the script, build a mental model of every character and location, then segment the narrative into visual beats, describing each one well enough that someone could draw it. For an 87-page script, that's days of careful, structured work.
The thing is, most of that work is extraction and cataloguing, not creative direction. The creative part is how you frame a shot, what you emphasize visually. But the inventory part, knowing that Louise Banks appears in scenes 3, 7, and 14, that she wears a hazmat suit in the first contact sequence, that the alien chamber has specific dimensions, all of that is essentially structured data extraction from unstructured text. And structured data extraction from text is exactly what LLMs are good at.
Four stages, one pipeline
The pipeline runs four sequential stages. Each one is backed by a compiled DSPy program trained against human-annotated gold data from three real screenplays: Arrival, Okja, and Whiplash.
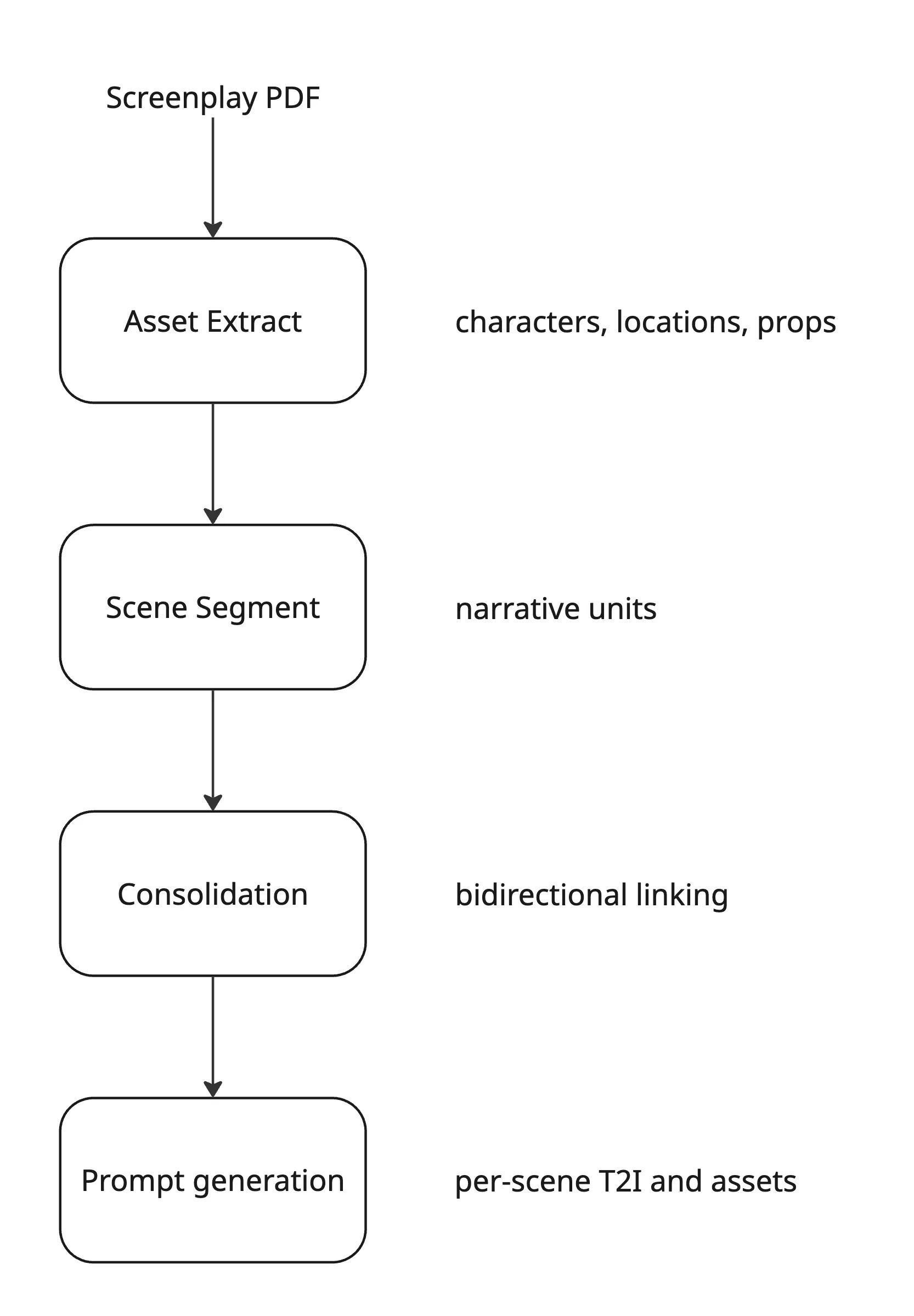
First, the Asset Extract stage reads the screenplay and pulls out every character, location, and prop, giving each a stable ID and a detailed physical description grounded in textual evidence. Second, the Scene Segment stage breaks the script into narrative units: establishing shots, character beats, conflicts, transitions. Third, the Consolidation stage links everything together bidirectionally, so each scene knows its assets and each asset knows its scenes. Finally, Prompt Generation takes all of that structured data and produces per-scene text-to-image prompts along with character look sheets.
The key property of this design is that assets are reusable. A character's visual description is defined once in stage one, linked to scenes in stage three, and referenced by prompts in stage four. Change the character's appearance in one place and every downstream prompt updates automatically.
DSPy instead of prompt engineering
The standard approach to LLM extraction is to write a system prompt, manually tune it until it works on your test cases, and hope it keeps working when the model changes. I wanted something more principled.
Every extraction task in this pipeline is expressed as a dspy.Signature, a typed interface that declares inputs, outputs, and field-level instructions. The optimizer (GEPA) then figures out the best prompting strategy automatically by training against the gold annotations.
class ScriptExtractionSignature(dspy.Signature):
"""Map screenplay text to structured extraction output."""
script_text: str = dspy.InputField(
desc="Complete screenplay or scene text to analyse for global entities."
)
extraction: ExtractionResult = dspy.OutputField(
desc="Structured extraction payload containing characters, locations, "
"and props. Extract physical_appearance as an ARRAY. First entry = "
"default appearance (age, hair, eyes, build, clothing). Additional "
"entries ONLY for major transformations (e.g., aging 20+ years)."
)
The result is a compiled JSON artifact checked into the repo. Prompt tuning becomes versioned, reproducible, and benchmarkable, rather than something that lives in someone's head.
For scene segmentation, I used dspy.ChainOfThought instead of plain Predict, which forces the model to reason explicitly before committing to segment boundaries. The difference in output quality was noticeable, especially for structurally complex sequences where a scene shifts tone without a clear cut.
class SceneSegmentationProgram(dspy.Module):
def __init__(self) -> None:
super().__init__()
self._predict = dspy.ChainOfThought(SceneSegmentationSignature)
def forward(self, screenplay_text: str) -> Prediction:
return self._predict(screenplay_text=screenplay_text)
Dealing with long scripts
A feature-length screenplay is 15,000 to 25,000 tokens. That fits in a modern context window, but sending the entire script in one call produces noticeably worse extraction. The model's attention degrades across very long inputs, and entities introduced early in the script start getting missed or confused with later ones.
The solution was incremental extraction with a running master list. The script gets split into roughly 3,000-token chunks, respecting paragraph and scene boundaries, and each chunk is processed with the accumulated results from all previous chunks passed as context.
def should_use_incremental_extraction(text: str, max_tokens: int = 3000) -> bool:
return count_tokens(text) > max_tokens
# Each chunk call looks like:
result = incremental_program(
chunk_text=chunk,
existing_elements=json.dumps(master_list) # grows with each chunk
)
master_list = result.extraction # merge new entities with existing ones
The IncrementalExtractionSignature instructs the LLM to reuse existing element_ids when the same entity appears again rather than creating duplicates. This turned out to be where most of the extraction quality came from. Without it, the model would happily create a new character entry every time someone was mentioned.
The sneaky hard part: character deduplication
Screenplays alias characters constantly. Arrival's linguist is referred to as LOUISE, DR. BANKS, THE LINGUIST, and LOUISE BANKS across different scenes. Without deduplication, the consolidation stage links her to scenes under four different identities, and suddenly your storyboard thinks there are four different women in the movie.
After extraction, a dedicated deduplication pass compares every character pair using name similarity, description overlap, and evidence from the text. Pairs above a 0.7 confidence threshold get merged, with the longer name kept as canonical and all evidence combined.
This was the single biggest quality improvement in the whole pipeline. Everything downstream, consolidation, prompt generation, the character sheets, all of it depends on having one entity per actual person.
Character sheets, not just prompts
The most useful output of the pipeline isn't actually the per-scene prompts. It's the character sheets.
Rather than generating one generic description per character, the prompt generator groups each character's appearances by segment type and emotional tone, then generates a separate visual variation for each unique context. A character in an action sequence looks different from the same character in a grief scene: different wardrobe, different body language, different lighting intent.
Each variation carries a title, emotional state, wardrobe notes, and a detailed image generation prompt. An artist or an automated image workflow can pull the exact variation they need for each scene without having to re-describe the character from scratch every time.
Results
I evaluated the pipeline against gold annotations from the three screenplays. Scene segmentation hit an F1 of 0.73 on average, ranging from 0.66 to 0.84 depending on the script, which was a four-point improvement over the zero-shot baseline after GEPA training. Element extraction came in at 0.58 F1 under strict case-insensitive name matching, with a wider range of 0.44 to 0.76. Processing a full feature-length screenplay costs roughly two to five dollars in API calls.
The output clears what I'd call the "creative team usability" bar. The storyboards need editing and artistic direction, but not reconstruction from scratch. The inventory work is done. A storyboard artist can spend their time on framing and composition instead of cataloguing who appears where.
What I'd do differently
The consolidation stage is the weakest link. Batching scene-to-asset linking at twenty scenes at a time causes boundary effects where assets that straddle a batch edge sometimes get dropped. A retrieval-augmented approach, embedding all assets and retrieving per scene, would be more robust than brute-force batching.
The F1 metric also penalized legitimate aliasing. Strict case-insensitive name matching counted Louise and DR. BANKS as two different entities during training evaluation, even when they're the same person. A fuzzy or embedding-based matching metric from the start would have given better training signal and pushed GEPA toward better deduplication earlier.
And finally, the Reflex frontend was an interesting experiment but not a production choice. Python-native reactivity is appealing in theory. In practice, the ecosystem is young and the debugging experience is painful. For anything client-facing, I'd reach for a standard framework next time.